

To scale AI in real P&C claims workflows reliably and without redesigning the core systems, you need an architecture that holds up to regulations, runs on what you already have, and never trusts independent decision-making to a single AI model.
There is little debate left about whether AI is useful for P&C insurance claims processing. From what I’ve seen in my practice and peers’ reports on pilots, FNOL processing can drop from 30–60 minutes to under 2 minutes, coverage verification can compress from 2–3 days to under 30 minutes, and simple claims can move from a 44-day cycle to 24–48 hours.
And yet, for most insurers, these results remain out of reach in day-to-day operations.
After years of working inside AI-focused claims transformation, I can say confidently that the failure to capture AI benefits doesn’t stem from lack of interest or lack of investment. Many carriers have already tried introducing AI into their operations. They have piloted use cases, tested vendors, and some even deployed point solutions.
What they have not done — at least not successfully — is move out of pilots towards scalable, production AI that can reliably cover the entire claims cycle.
Together with Vadim Belski, ScienceSoft’s Head of AI and Principal Architect, we spent the last two years answering a very specific question: which AI architectures actually hold up in production claims environments, and which ones only work in demos.
The Hidden Failure Points of Stitching Single-Task AI Tools
Most AI initiatives in claims start with a reasonable assumption: if you improve individual steps, the overall process improves as well. So organizations begin with targeted use cases like automating FNOL intake, extracting data from documents, or drafting communications.
Each of these targeted AI tools can perform well in isolation. The problems begin when you connect them for end-to-end claims automation.
A typical claim may involve eight or more processing steps. Even if each AI-driven step operates at 95% accuracy (which is optimistic but possible), the combined reliability drops significantly by the time the claim reaches a decision point. Errors accumulate and reinforce one another. Incorrect data extraction leads to wrong coverage analysis. That data feeds into summaries and claim decisions that appear coherent but are fundamentally flawed. By the time the adjuster reviews the file, the issue is no longer obvious.
What makes this particularly difficult to manage is that these failures are rarely visible as failures. They present as plausible AI outputs.
Why Looking for One “Smart” AI Model is the Wrong Answer
One common question I hear from clients is: can’t we solve this with a single, highly capable large language model (LLM) that would process documents, interpret policies, analyze images, and give us one consolidated answer?
In practice, that approach introduces even more risk.
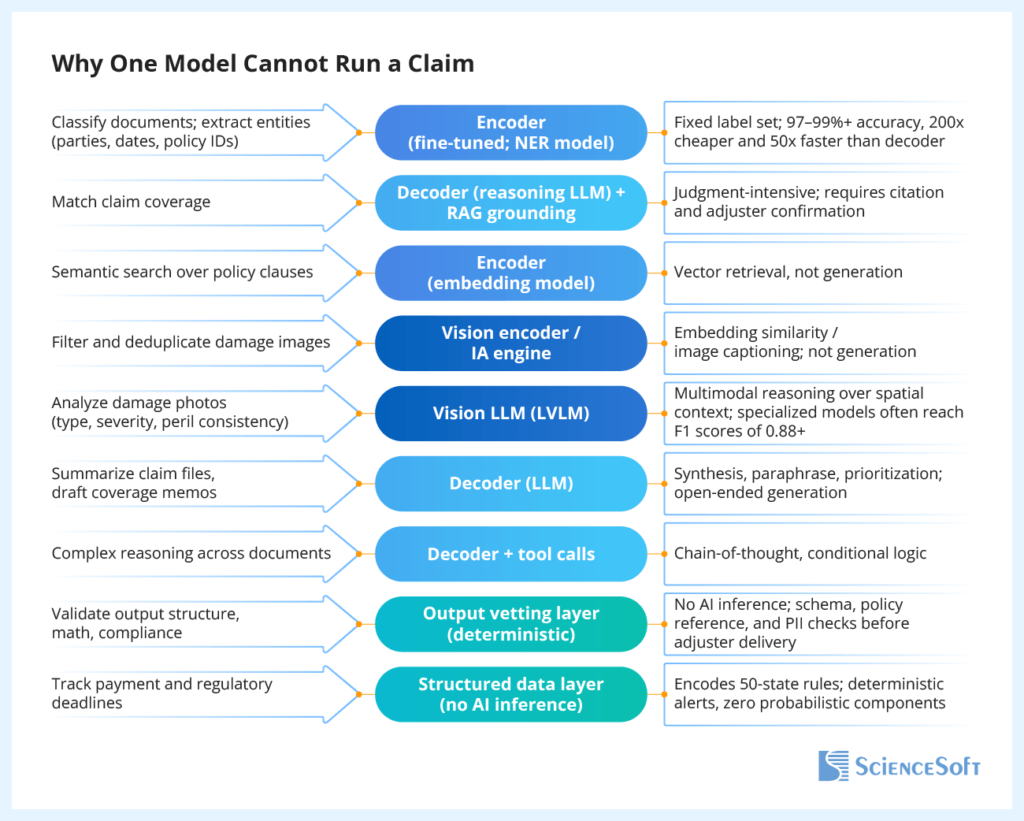
Different tasks within the claim cycle require different types of AI computation. Classifying a document into a known category is a closed-ended problem that fine-tuned encoders can solve quickly, cheaply, and with high accuracy. Interpreting coverage, on the other hand, is a complex task that demands a nuanced reading of policy language and strong LLM reasoning. Analyzing damage from images introduces another dimension, requiring models that understand spatial and visual context.
Trying to force all of these into a single model leads to compromises everywhere: lower reliability, higher costs, and less control. Moreover, there are parts of the claims workflow, such as deadline compliance control, where simple algorithmic rules still work best. Inherently non-deterministic AI models alone cannot provide consistent, auditable, and defensible automation here.
A Realistic AI Architecture We Arrived At
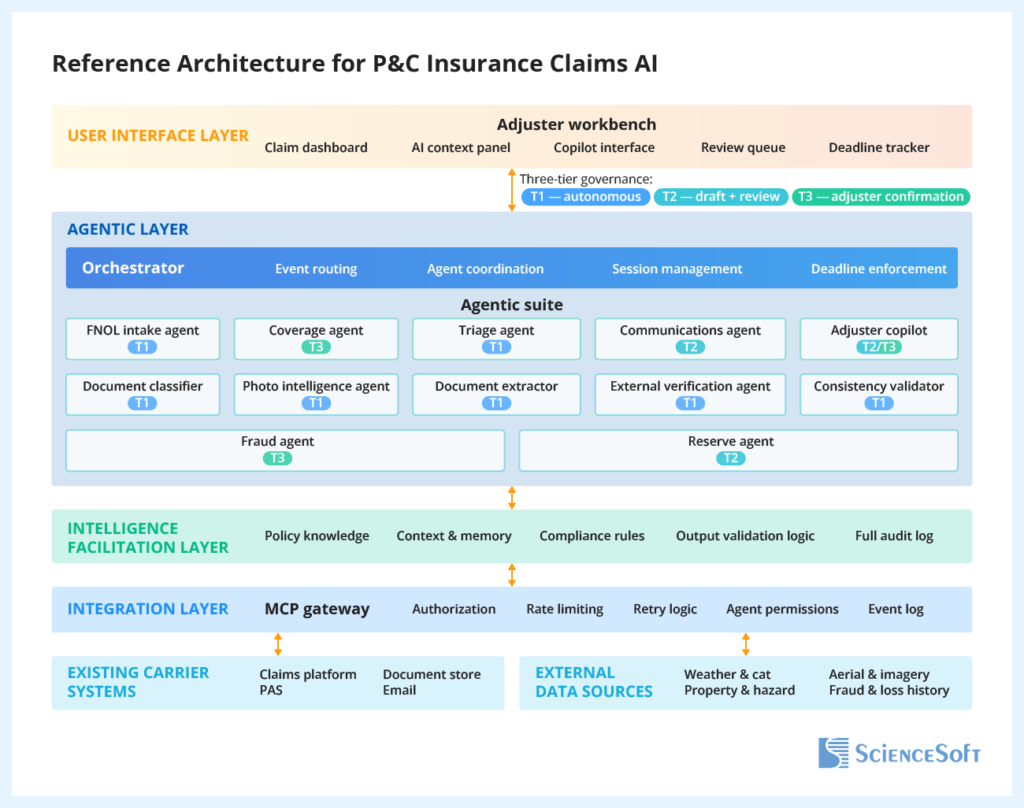
At a high level, the P&C claims AI architecture we propose is built around five components.
At the center is the adjuster workbench, the environment where the adjuster operates. Instead of navigating multiple systems and manually assembling a claim file, the adjuster works from a single screen that surfaces coverage analysis, document summaries, fraud signals, compliance deadlines, and reserve recommendations. The adjuster reviews and decides, but they no longer need to build the file from scratch.
Behind that interface sits what we call the agentic suite — a set of specialized agents, each with a clearly defined job in the claims process. They are not generic AI models, they do not share a single “brain”, and they are not tightly coupled. Each agent is purpose-built and independently deployable. This separation wins operationally and from a governance standpoint: it lets us clearly define each agent’s access rights and limit the agent’s ability to improvise outside its assigned function. I’ll come back to why this matters later in the article.
Connecting these agents to the existing environment is a unified integration layer. This is a controlled gateway into your claims platforms, policy administration systems, document repositories, and external data sources. Every interaction passes through this boundary, and every action is authenticated and logged, creating a complete audit trail.
Making these work together is the orchestrator. This is the system’s coordination center. It receives every event (a new FNOL, a document upload, an adjuster action, and so on) and determines which agents should be activated, in what sequence, and under what conditions. It also enforces regulatory timelines across all jurisdictions. The orchestrator is not a “super-agent”. It sits outside the agentic suite and combines workflow logic, business rules, confidence thresholds, and event-based triggers to decide how the process should move forward and when additional checks are needed, operating with its own boundaries
A dedicated intelligence facilitation layer hosts grounded policy knowledge, session-state memory, compliance rules, and deterministic output validation logic shared across the workflow. This layer also maintains the full governance and audit framework for the system.
Role-Specific AI Agents Behind Claims Automation
Automation is driven by a coordinated set of agents that map directly to the stages of claims workflow.
We typically organize them into two layers.
The base suite automates core adjuster tasks across the claims workflow. The intake agent extracts structured data from FNOLs and matches it to policies. The coverage agent reads the full policy and drafts a coverage position. The triage agent scores claims and routes them to the right execution pipeline based on severity. The communications agent drafts claimant correspondence (acknowledgments, coverage decisions, denial letters, and so on). This suite also includes the adjuster copilot, a conversational assistant that gives adjusters live, context-aware guidance across claims.
On top of that sits the agentic investigation layer. The document classifier classifies, quality-scores, and deduplicates incoming documents, triggering follow-up requests for missing ones. The document extractor parses estimates and inspection reports into structured data. The photo intelligence agent analyzes damage photos for damage type, severity, and consistency with the reported peril. The external verification agent cross-checks third-party data, such as weather records and aerial imagery, against the claim. The consistency validator compares inputs and flags conflicts, and the fraud agent scores fraud for SIU, immediately escalating high-risk cases. Finally, the reserve agent produces reserve suggestions based on the claim context and comparable closed claims.
What Makes This Architecture Production-Ready
- It employs the right tool for each task
Each component of the agentic system in the reference setup uses the best-fitting AI model for each task and avoids AI altogether when it is not needed.
For example, document classification is handled by fine-tuned encoder models with fixed label sets, reaching very high accuracy at a fraction of the cost of generative models. Semantic search over policy clauses and named entity extraction (parties, dates, policy numbers) are also handled by specialized encoders, delivering high precision at high speed. These models don’t generate anything, so there’s no hallucination risk at this step.
For coverage analysis and reasoning over submissions, we use decoder LLMs with retrieval-augmented generation (RAG) so outputs are grounded in actual policy text with citations; the human adjuster should still review and confirm the decision at the final step. Memo and communication drafting also relies on decoders and vector retrieval for grounded data synthesis and accurate open-ended generation.
Photo deduplication and filtering can employ traditional image analysis engines or vision encoders drawing on semantic alignment between images and associated text. For actual damage assessment, we use vision language models (LVLMs) capable of multimodal reasoning over spatial context.
Regulatory compliance control is an area where we do not use AI at all. Automation is enforced through deterministic rules. Same rule-based engines handle output validation (structure, references, numerical consistency, etc.) before anything reaches the adjuster.
- It breaks the error propagation chain early
Unlike loosely connected AI tools, this architecture forms a coordinated system where outputs at every step are verified and grounded before they become inputs to the next step. Each agent operates within clearly defined boundaries, and no single output is treated as the truth without validation. Taking a property claim as an example, downstream agents would receive the outputs of FNOL intake and document extraction as settled facts together with confidence scores and validation metadata.
Suppose the intake agent identifies a contractor estimate with low confidence because the uploaded file is partially scanned and overlaps with a proof-of-loss form. The document classifier would trigger a secondary extraction pass, compare the document against prior estimates or policyholder submissions for consistency, or route the file to the adjuster for review before coverage analysis continues.
If the workflow proceeds, the coverage agent does not generate conclusions freely: it retrieves the relevant policy clauses, cites them explicitly, and checks extracted loss details against policy structures and prior claim records. And before the adjuster sees anything, deterministic validation rules check calculations, state-specific wording, missing fields, and structural consistency. The consistency validator withholds anything that does not meet the required standards and escalates this for review.
- It supports safe and governed AI usage
In this architecture, we use a three-tier governance model. Low-risk, routine actions (intake, document classification) run automatically. Operational outputs like acknowledgment letters can be released automatically unless an adjuster flags or edits them within a short review window. High-impact decisions, such as coverage determinations, denials, and fraud escalations, require explicit adjuster approval before anything is finalized. This approach keeps automation aligned with operational risk, retaining human control over decisions that carry regulatory, financial, or litigation exposure.
To support a regulator-ready audit trail, the system logs every action, including inputs, outputs, agent actions, source references, confidence scores, validations, and adjuster overrides. With this complete log, you can explain how decisions were reached, trace recommendations back to supporting evidence, and review model behavior long after a claim is closed, all in alignment with state DOI requirements and the NAIC AI Model Bulletin guidelines. Over time, adjuster overrides also become a valuable feedback loop, capturing institutional knowledge and improving agent performance.
Constraining each agent to a narrowly defined job makes the system inherently easier to govern. You always know which agent produced which output, under what logic, and with what level of confidence. It also makes model drift, inconsistent behavior, or anomalous outputs easier to detect and isolate before they become systemic problems.
- It works on top of what you already have
A common misconception among ScienceSoft’s insurance clients is that claims AI requires a modern claims management system to host new technology components. With over 70% of US claims organizations still operating on fragmented or outdated technology stacks, it’s no surprise most carriers have not moved AI out of localized pilots.
We designed our architecture to avoid dependency on existing core systems. The proposed agent workbench sits on top of your current infrastructure and acts as an operational layer between your systems without replacing them or requiring expansion.
You can connect the agentic system with your internal systems and selected external platforms through a lightweight integration layer combining APIs, event-driven messaging, and secure data access adapters. Exposing the integration layer through a single MCP gateway, like we do in our architecture, simplifies integration across fragmented environments and supports a consistent audit trail required for compliance. When API-based integration is unavailable, you can apply tailored extraction approaches, such as database views, RPA-assisted access, and ingestion pipelines.
- It allows for incremental rollout
Another barrier is the perception that AI-driven claims transformation is a multi-year challenge.
The architecture we propose enables the AI system to run alongside existing workflows from day one, gradually assuming more responsibility as confidence grows. Each agent runs as a separate service. You can deploy one, a subset, or the full suite. The system does not require an all-or-nothing commitment.
You can start with a limited set of capabilities, say, intake and coverage analysis, and expand from there. Within a few months, you can introduce additional components such as triage, document intelligence, and communication automation. As the system matures, more advanced investigation and verification capabilities can be added.
This phased deployment provides a practical path to move AI out of pilot environments. From my experience, you can have a base suite of agents processing real claims with adjuster oversight in as little as 6 months.If you’re wondering what an incremental AI build would look like for your claims volume and current adjustment process, contact ScienceSoft’s team to discuss your case.
Author – Vital Soupel, Senior Insurance IT & AI Consultant at ScienceSoft



